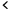In today’s data landscape, a modern data warehouse empowers us to effortlessly handle diverse data types and volumes. This data is then made accessible to end-users through various analytical tools, including dashboards, reports, and advanced analytics. As Azure Synapse gains traction, there’s a notable surge in interest in modernizing conventional Business Intelligence (BI) data platforms.
Traditionally, modernization often revolves around utilizing tools like Power BI. However, this approach primarily addresses the end-user layer, encompassing data models, reports, and dashboards. While Power BI can evolve into a modern data platform, covering stages like data ingestion, ETL, storage, processing, and serving, it has limitations, particularly in complex data ingestion and transformation scenarios.
With Azure Synapse, we find a more comprehensive solution. It offers the flexibility and scalability to build a modern, agnostic data platform alongside Power BI, bridging gaps and enhancing capabilities for data ingestion, transformation, and access by other teams, such as data science.
In this blog post, we’ll demonstrate building a Lakehouse architecture using Azure Synapse Analytics, departing from conventional BI methods.
In this architecture, we will use a data lake, Azure Data Lake Storage Gen2, to store the data in files, instead of a relational database. It is a low-cost storage solution that contains a set of capabilities dedicated to big data analytics.
This is an example of a high-level lakehouse architecture:

In the data lake, we usually structure data into folders or layers based on its refinement level, ensuring an organized system for easier management and access.
The challenge with this approach was how the data lake could handle the capabilities provided by the data warehouse. Delta format turned out to be the solution for providing ACID transactions and CRUD operations (deletes and upserts) to the data lake.
Azure Synapse Analytics serves as a versatile toolset, equipping us with everything necessary to load various layers and execute transformations. It offers a unified analytics platform where different tools and capabilities can seamlessly collaborate during the ingest and preparation phases. This flexibility allows us to select the most suitable tool for each task without the hassle of integrating multiple tools. For instance, we can orchestrate the execution of pipelines containing Databricks and/or Spark notebooks effortlessly.
Let’s now look at loading each layer in more detail.
As we want to copy raw data from our data sources, a great choice for data ingestion is Azure Synapse Pipelines, almost the same as Azure Data Factory (ADF) but with some minor differences.
When the data source is a relational store, our recommendation is to use the meta-driven copy task. This is a tool that allows us to build dynamic pipelines that will use the metadata stored in the control table. This metadata contains the name list of the tables to copy with the required synchronised pattern (full or incremental).
In short, we have a built-in framework that acts as an accelerator to our development efforts, and, at the same time, helps us to reduce the number of pipelines and tasks to maintain.
You can find more information in the official documentation.
We will need to apply transformations in order to load the silver and gold layers. Azure Synapse is a great flexible platform because we can choose and combine different computing environments.
The most common is SQL compute, which comes in two flavours: serverless and dedicated SQL pools.
With serverless, we can transform data by using T-SQL views and create external tables on top of the data lake; the main difference is that external tables store the transformed data in files in the data lake. With T-SQL views we can even build a logical data warehouse without storing the converted data. At the same time, the serverless pool can act as a serve layer in the same way that Azure SQL Server does.
We can also use T-SQL to ingest data from Azure Blob Storage or Azure Data Lake into tables in the SQL pool. By creating external tables, we can access files as if they were structured tables and load them into tables using PolyBase. There are other options such as BCP and SQL BulkCopy API, but the fastest and most scalable way to load data is through PolyBase. This option will “break” our data lakehouse architecture because we will store the data in tables in a database, instead of the data lake. Of course, the SQL pool is extremely useful for some big data scenarios, for example when we need to serve big data to Power BI in any storage mode: import, direct query, or dual mode.
Transitioning our data lake into the primary data warehouse presents a significant challenge, particularly concerning the complexity of updating or deleting Parquet files. Fortunately, the Delta format offers a solution to these issues, enabling such operations while also providing ACID transactions akin to those in a traditional database. It’s worth noting that the term “Delta lake” refers to a data lake employing the Delta format.
Azure Synapse Analytics equips us with the necessary tools to implement the lakehouse pattern atop Azure Data Lake Storage. We utilize Synapse pipelines to orchestrate the loading and transformation stages, leveraging a variety of technologies that seamlessly integrate with Delta: Databricks, Mapping Dataflows, and Spark.
Mapping Dataflows offer a code-free approach to crafting data transformations, seamlessly translating into Spark notebooks executed within scaled-out Spark clusters, making it Delta-compatible.
Moreover, we have the option to configure a serverless Apache Spark pool, allowing us to script data transformations using Python, Scala, Java, or C# within notebooks.
Azure Synapse is accessible from Azure Databricks via a shared Blob storage container, facilitating data exchange between Databricks clusters and Synapse instances. This interoperability extends to scenarios such as integrating image and video data into our data warehouse or enabling our Machine Learning team to develop advanced analytics algorithms with Databricks, eliminating the need for intricate integration operations.
While SQL serverless pools can read Delta-format files, they currently lack the capability to perform merge operations, rendering SQL unsuitable as a transform compute option for Delta files.
In this article we have reviewed the different options that Azure Synapse Analytics offers us to modernise or build our data platform.
To make the right choices for storage, computing, and serving, understanding all components is crucial. Factors like data volume, type, transformation complexity, processing and storage costs, access requirements for applications and teams (like ML), and the team’s programming expertise determine the best fit. Therefore, it’s vital to have a good grasp of the available tools to select the most suitable ones for our needs.
And don’t forget that Synapse is not only for big data projects: we can start small but think big in the mid- to long-term, because we can leverage the cloud to scale fast. Wherever and whenever we need the extra power (ingestion, transformation, compute, processing, serve, etc.), we are just a click away.
If you need help selecting the right data platform architecture, technologies, and methodologies for your organization, feel free to reach out to us. Our expert consultants are here to assist you promptly!